Intervalos de Confiança
Inferência estatística e parâmetros
A inferência estatística consiste em fazer afirmações sobre características de uma população a partir de amostras desta. Estudaremos diversos métodos de inferência estatística.
Para que seja possível fazer inferência estatística, a probabilidade descreve como a amostra se relaciona com a população. Por exemplo, considere uma população de processos similares em que a frequência de procedência da ação é uma quantidade desconhecida, \(\theta\). Tomando uma amostra de \(10\) processos desta população, as indicadoras de procedência na amostra podem ser denotadas por \(X_1, \ldots, X_{10}\). Dizemos que a distribuição de uma variável com probabilidade \(\theta\) de assumir o valor \(1\) e \(1-\theta\) de assumir o valor \(0\) é uma \(\text{Bernoulli}(\theta)\) e escrevemos \(X_i \sim \text{Bernoulli}(\theta)\). Nesta afirmação, note que \(X_i\) refere-se à amostra e \(\theta\) refere-se à população. Assim, a expressão “\(X_i \sim \text{Bernoulli}(\theta)\)” tece a relação entre a amostra e a população.
Existem duas abordagens distintas para a Inferência Estatística. Elas variam de acordo com a interpretação de probabilidade usada. Segundo a interpretação frequentista, \(\theta\) é uma frequência populacional fixa e desconhecida. Neste sentido, afirmações probabilísticas referem-se somente à amostra. Por outro lado, segundo a interpretação subjetivista, como \(\theta\) é um quantia desconhecida, há incerteza sobre ela. Neste sentido, é possível fazer afirmações probabilísticas relativas à incerteza sobre \(\theta\). Embora ambas as abordagens sejam úteis, este curso focará principalmente na abordagem frequentista.
Intervalos de Confiança
Em algumas situações, desejamos criar um intervalo pequeno tal que seja bastante plausível que o parâmetro esteja dentro dele. Por exemplo, considere que estamos estudando a frequência da procedência da ação em uma população de processos, \(\theta\). A frequência da procedência na amostra é uma estimativa plausível para \(\theta\). Contudo, é implausível que \(\theta\) seja exatamente igual à frequência amostral. Assim, além desta estimativa, podemos considerar uma estimativa “conservadora” e outra “otimista” de \(\theta\). O conjunto de valores entre a estimativa conservadora e a otimista é um intervalo de valores plausíveis para \(\theta\). A seguir, veremos formalmente como operacionalizar esta ideia.
O primeiro passo consiste em observar que um intervalo é constituído por um limite inferior, \(L_1\), e um limite superior \(L_2\). Assim, construir intervalos consiste em escolher \(l_1\) e \(l_2\) baseados na amostra. Para cumprir nossos objetivos, gostaríamos que \(L_2-L_1\), o comprimento do intervalo, fosse pequeno. Também gostaríamos que, antes de a amostra ser observada, a probabilidade de \(\theta\) estar dentro do intervalo fosse grande, \(P(L_1 < \theta < L_2) > 1-\alpha\), para um \(\alpha\) pequeno. Após obtida a amostra, dizemos que o intervalo obtido tem confiança \(1-\alpha\) para \(\theta\).
Atenção: A probabilidade de \(1-\alpha\) refere-se ao método para a obtenção do intervalo, em um momento anterior à coleta da amostra. Em outras palavras, se coletarmos um número muito grande de amostras, em aproximadamente \(1-\alpha\) destas \(\theta\) estará dentro do intervalo de confiança obtido. Por outro lado, uma vez que uma particular amostra é obtida, não é mais verdade que a probabilidade de \(\theta\) estar no intervalo é \(1-\alpha\). Podemos afirmar apenas que, ou \(\theta\) está no intervalo, ou \(\theta\) não está no intervalo (e não sabemos qual das afirmações é verdadeira). Por isso que dizemos que o intervalo obtido tem confiança \(1-\alpha\). A confiança refere-se ao método usado para construir o intervalo e não ao intervalo obtido.
Amostra Bernoulli
Considere que \(X_1, \ldots, X_n\) são as indicadoras de procedência em ações independentes obtidas de uma população em que a proporção desconhecida de procedência é \(\theta\). Vimos que podemos escrever esta afirmação da seguinte forma compacta: \(X_1,\ldots,X_n\) independentes e \(X_i \sim \text{Bernoulli}(\theta)\). Neste caso, considerando que \(\bar{X}\) é a média amostral, o seguinte intervalo é comumente usado:
\[IC_{1-\alpha} = \left[\bar{X} - \frac{z_{1-0.5\alpha}}{2\sqrt{n}}; \bar{X} + \frac{z_{1-0.5\alpha}}{2\sqrt{n}} \right],\]
onde \(z_{1-0.5\alpha}\) é um valor tabelado que corresponde ao percentil \(1-0.5\alpha\) da distribuição normal. Nesta fórmula o comprimento do intervalo é \(\frac{z_{1-0.5\alpha}}{\sqrt{n}}\). Também, o intervalo é centrado na frequência amostral. A distância entre a frequência amostral e os extremos do intervalo é chamada de “margem de erro” e tem o tamanho \(\frac{z_{1-0.5\alpha}}{2\sqrt{n}}\).
Frequência de assunto processual
O código abaixo apresenta um intervalo de confiança 95% para a frequência de processos com o assunto “Práticas Abusivas”:
library(tidyverse)
library(readxl)
data = read_xlsx("./dados_civeis.xlsx") %>%
select(-processo_por_dependencia)
X = data %>%
mutate(assunto_escolhido = assunto_info == "Práticas Abusivas") %>%
select(assunto_escolhido) %>%
unlist()
n = length(X)
media = mean(X)
margem = qnorm(0.975)/(2*sqrt(n))
intervalo = c(mean(X)-margem, mean(X)+margem)
print("Intervalo de Confiança:")## [1] "Intervalo de Confiança:"print(round(intervalo, 3))## [1] 0.103 0.126A frequência amostral deste assunto é 0.115 e o tamanho da amostra é 6888. Aplicando a expressão apresentada acima, obtemos que a margem de erro é 0.012 e, assim, os limites inferior e superior do intervalo de confiança são 0.103 e 0.126. Note que é incorreto interpretar que há probabilidade de 95% de a frequência populacional estar entre 0.103 e 0.126. Podemos interpretar que, se gerarmos vários bancos de dados independentes da mesma população, então \(\theta\) pertencerá a cerca de 95% dos intervalos gerados por meio destes bancos de dados. Contudo, após um particular banco de dados ser coletado, ou \(\theta\) está dentro do intervalo calculado ou não está. A confiança de um particular intervalo gerado não é a probabilidade de que o parâmetro pertença a ele.
Taxa de reforma em câmaras criminais
Intervalos de confiança são comumente utilizados para comparar se grupos distintos apresentam o mesmo comportamento em relação a uma determinada variável. Para ilustrar este conceito, considere a taxa de reforma de sentenças criminais em recursos ajuizados pelo réu. O gráfico a seguir apresenta um intervalo de confiança para a taxa de reforma cada Câmara Criminal em São Paulo:
alpha = 0.05
camaras = read_csv('./camaras.csv')
aux = camaras %>%
filter(polo_mp == "Passivo") %>%
mutate(reforma = decisao %in% c("Provido", "Parcialmente")) %>%
group_by(camara) %>%
summarise(taxa_reforma = mean(reforma), n_dados = n()) %>%
ungroup() %>%
filter(n_dados >= 100) %>%
mutate(
se = sqrt(taxa_reforma * (1 - taxa_reforma) / n_dados),
lower = taxa_reforma - qnorm(1-0.5*alpha) * se,
upper = taxa_reforma + qnorm(1-0.5*alpha) * se
) %>%
mutate(camara = gsub("de Direito Criminal", "", camara))
aux %>%
ggplot(aes(x = camara, y = taxa_reforma)) +
geom_point(size = 3, color = "blue") + # Mean points
geom_errorbar(aes(ymin = lower, ymax = upper), width = 0.2, color = "red") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 30, hjust = 1)) +
ylab("Taxa de Reforma") +
xlab("Câmara de Direito Penal")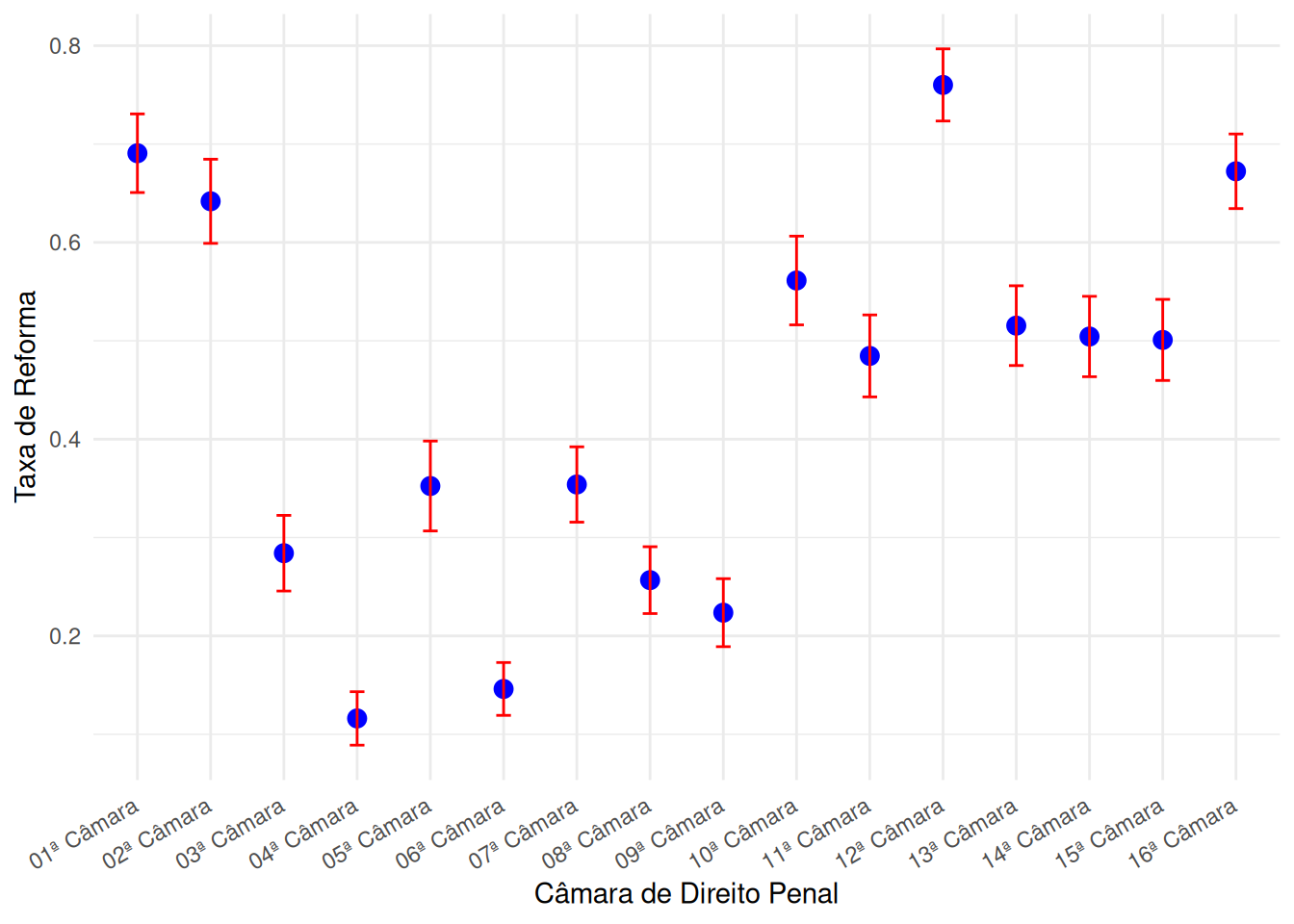
Os pontos azuis indicam a taxa de reforma empírica que foi observada para cada Câmara. Existem duas possíveis explicações quando uma taxa de reforma é maior do que outra: ou uma Câmara sistematicamente reforma sentenças mais frequentemente do que outra, ou este padrão é observado na amostra por mera flutuação aleatória dos dados. Podemos utilizar os intervalos de confiança para diferenciar entre estes casos.
Por um lado, podemos comparar as taxas de reforma da \(1^a\) e da \(2^a\) Câmaras. Na amostra, observamos que a taxa de reforma da \(1^a\) Câmara é maior do que aquela da \(2^a\). Contudo, observamos que seus respectivos intervalos de confiança assumem valores em comum. Isto é, é plausível que as taxas de reforma populacionais de ambas as Câmaras sejam iguais. Assim, não encontramos indícios suficientemente fortes de que as taxas de reforma populacionais destas Câmaras sejam distintos.
Por outro lado, podemos comparar as taxas de reforma da \(1^a\) e da \(4^a\) Câmaras. Novamente, a taxa de reforma da \(1^a\) Câmara na amostra é maior do que aquela da \(4^a\). Além disso, neste caso, os intervalos de confiança para as taxas de reforma populacionais não assumem valores em comum. Isto é, não é plausível que as taxas de reforma populacionais de ambas as Câmaras sejam iguais. Assim, há indícios fortes de que a taxa de reforma populacional da \(1^a\) Câmara é maior do que aquela da \(4^a\).
Amostra Normal
Considere que \(X_1, \ldots, X_n\) são variáveis quantitativas, como o valor da causa. Neste caso, é comum assumirmos que cada \(X_i\) tem distribuição normal e escrevemos \(X_i \sim N(\mu, \sigma^2)\). Assim como no caso da amostra Bernoulli, esta expressão conecta a amostra à população. Decorre desta suposição que \(\mu\) e \(\sigma^2\) são, respectivamente, a média e a variância populacional desta variável quantitativa. Neste caso, obtemos o seguinte intervalo de confiança para \(\mu\):
\[IC_{1-\alpha} = \left[\bar{X}-\frac{S\cdot qt(1-0.5\alpha,n-1)}{\sqrt{n-1}}, \bar{X}+\frac{S \cdot qt(1-0.5\alpha,n-1)}{\sqrt{n-1}}\right],\]
onde \(qt(1-0.5\alpha,n-1)\) é um valor tabelado referente ao quantil \(1-0.5\alpha\) da distribuição \(T_{n-1}\).
O gráfico a seguir apresenta intervalos de confiança para o valor da causa para os \(10\) assuntos mais frequentes em ações cíveis:
library(readxl)
data_civeis = read_xlsx("./dados_civeis.xlsx") %>%
select(-processo_por_dependencia)
assuntos_freq = names(sort(table(data_civeis$assunto_info), decreasing = TRUE)[1:10])
aux = data_civeis %>%
filter(valor_numerico < 10^5) %>%
mutate(
assunto_novo = ifelse(assunto_info %in% assuntos_freq,
assunto_info,
"outros")
) %>%
group_by(assunto_novo) %>%
summarise(
media_vcausa = mean(valor_numerico),
var_vcausa = var(valor_numerico),
n_dados = n()
) %>%
ungroup() %>%
mutate(
se = sqrt(var_vcausa / n_dados),
lower = media_vcausa - qnorm(1-0.5*alpha) * se,
upper = media_vcausa + qnorm(1-0.5*alpha) * se
)
aux %>%
filter(assunto_novo != "outros") %>%
ggplot(aes(x = assunto_novo, y = media_vcausa)) +
geom_point(size = 3, color = "blue") + # Mean points
geom_errorbar(aes(ymin = lower, ymax = upper), width = 0.2, color = "red") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 30, hjust = 1)) +
ylab("Valor da Causa") +
xlab("Assunto")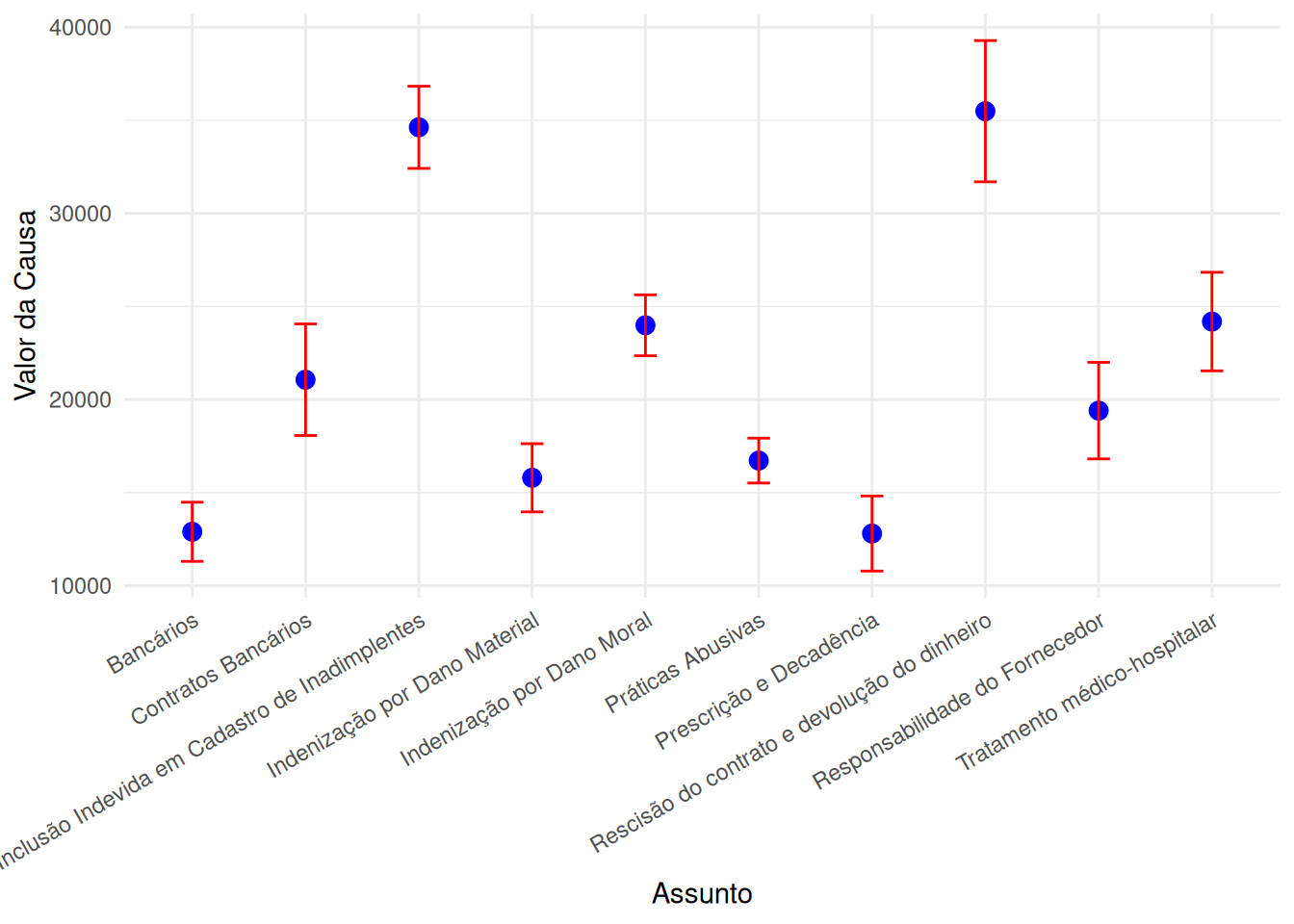
Estes intervalos podem ser interpretados similarmente àqueles obtidos para taxas de reforma em Câmaras Criminais. Quais conclusões você consegue tirar deste gráfico?
A Interpretação de Intervalos de Confiança
Para interpretar corretamente intervalos de confiança, um experimento mental pode ser útil. Considere cada um de \(10.000\) pesquisadores coleta dados sobre \(100\) processos distintos da mesma população. Se cada pesquisador construir um intervalo de confiança 95% para o valor da causa, então cerca de \(9.500\) dos pesquisadores construirá um intervalo que cobre a média populacional para o valor da causa. Este experimento mental pode ser simulado da seguinte forma:
alpha = 0.05
mu = 20000
sigma = 150
n = 100
num_experimentos = 10000
sucessos = 0
for(ii in 1:num_experimentos)
{
dados = rnorm(n, mu, sigma)
l1 = mean(dados) - sigma/sqrt(n) * qnorm(1-0.5*alpha)
l2 = mean(dados) - sigma/sqrt(n) * qnorm(0.5*alpha)
sucessos = sucessos + (mu > l1 & mu < l2)
}
sucessos/num_experimentos## [1] 0.9472Exercícios
Defina e interprete intervalo de confiança em suas próprias palavras.
Um experimentalista experiente realizou \(9\) medições da largura de um objeto usando um paquímetro. A média destas observações foi de \(1.2 mm\). O desvio padrão do experimentalista com o paquímetro é de \(0.2 mm\). Usando estas informações, construa intervalo com confiança 90%, 95% e 99% para a largura do objeto.
No exemplo da normal com variância conhecida, obtemos que o comprimento do intervalo de confiança é \(\frac{2\sigma_0 qnorm(1-0.5\alpha)}{\sqrt{n}}\). Isto ocorre pois \(qnorm(0.5\alpha)=1-qnorm(1-0.5\alpha)\). Interprete \(\sigma_0\), \(\alpha\) e \(n\) e como estas quantidades inluenciam no tamanho do intervalo de confiança.
O caso da normal com variância populacional conhecida é um caso especial do caso da normal com variância populacional desconhecida. Em particular, o intervalo de confiança obtido para a variância populacional desconhecida é válido mesmo quando ela é conhecida. Apesar disso, é indesejável usar este intervalo neste caso. Por quê?
Obtenha a linha de raciocínio completa para obter o intervalo de confiança no caso da normal com variância desconhecida.