Testes de Hipótese
É comum que queiramos saber o quanto uma amostra corrobora uma hipótese científica. Neste caso, podemos aplicar um teste de hipótese, isto é, um procedimento que decidirá se a hipótese é ou não rejeitada diante da amostra obtida. A hipótese que está sendo testado é comumente chamada de hipótese nula, \(H_0\).
Por exemplo, considere que \(X_1, \ldots, X_n\) indicam a procedência em processos independentes e que \(X_i \sim \text{Bernoulli}(\theta)\). Uma possível hipótese é a de que a taxa populacional de procedência é 50%, isto é \(H_0: \theta = 0.5\).
Tipos de erro
Existem \(4\) possíveis resultados que podem decorrer de um teste de hipótese. Note que o teste de hipótese pode rejeitar ou não rejeitar a hipótese nula e, também, esta hipótese pode ser verdadeira ou falsa. Assim, existem \(4\) combinações de resultados possíveis:
- (Acerto) A hipótese nula é verdadeira e não é rejeitada.
- (Acerto) A hipótese nula é falsa e é rejeitada.
- (Erro tipo I) A hipótese nula é verdadeira e é rejeitada.
- (Erro tipo II) A hipótese nula é falsa e não é rejeitada.
Note que existe um balanço entre os erros tipo I e II. Por exemplo, se quiséssemos que a probabilidade de cometer um erro tipo I fosse 0, então poderíamos nunca rejeitar H. Contudo, neste caso, a probabilidade de cometerum erro tipo II seria 1. Analogamente, se sempre rejeitarmos H, então as probabilidades de erro tipo I e II serão, respectivamente, 1 e 0. Na prática, rejeitamos \(H_0\) quando os dados oferecem evidência contrária a este hipótese. Assim, buscamos que as probabilidades de cometer um erro tipo I ou um erro tipo II sejam baixas.
Uma outra observação importante é que, em geral, não sabemos se cometemos um erro em um teste de hipótese. Para saber se \(H_0\) é verdadeiro ou não, seria necessária observar a população. Como usualmente só somos capazes de observar a amostra, não somos capazes de determinar se \(H_0\) é verdadeiro ou não. Assim, não sabemos se o resultado do teste de hipótese foi um acerto ou um erro.
Apesar da limitação acima, podemos controlar as probabilidades de erro tipo I e II de um teste. Isto é, podemos desenvolver testes que, antes de observar o banco de dados, tenham uma baixa probabilidade de cometer um erro.
Convecionou-se que a hipótese nula deve ser escolhida de tal forma que o erro tipo I seja mais grave que o erro tipo II. Por exemplo, pode ser mais grave concluir que um rio não está poluído quando ele está poluído do que concluir que ele está poluído quando de fato não está. Assim, neste caso, tomaríamos a hipótese nula como aquela de que o rio está poluído, pois assim o erro tipo I seria o de rejeitar que o rio está poluído quando ele de fato está. Similarmente, a hipótese científica tomada como hipótese nula geralmente é o status quo.
Como o erro tipo I é o mais grave, construímos testes de hipótese que diretamente controlam a probabilidade de erro tipo I. Formalmente, determinaremos testes de hipótese tais que o erro tipo I seja menor que um valor pré-determinado, \(\alpha\). É comum que \(\alpha\) seja chamado de nível de significância do teste.
Exemplo: Amostra Bernoulli
Considere que \(X_1, \ldots, X_n\) indicam a procedência em processos independentes e que \(X_i \sim \text{Bernoulli}(\theta)\). Uma possível hipótese é a de que a taxa populacional de procedência é 50%, isto é \(H_0: \theta = 0.5\). Para controlar o erro tipo I em \(\alpha\), rejeitamos \(H_0\) se
\[|\bar{X}-0.5| > \frac{0.5 \cdot qnorm(1-0.5\alpha)}{\sqrt{n}}.\] Observação: Verifique \(H_0\) é rejeitado quando o intervalo de confiança 95% para \(\theta\) não contém o valor \(0.5\).
O exemplo a seguir estuda a taxa de reforma de sentenças por Câmaras Criminais em recursos nos quais o Ministério Público é polo passivo. Para cada Câmara, testa-se a hipótese que a taxa de reforma é 50%.
library(tidyverse)
read_csv("./camaras.csv") %>%
mutate(
reforma = decisao %in% c("Parcialmente", "Provido"),
camara = gsub(" de Direito Criminal", "", camara)
) %>%
group_by(camara, polo_mp) %>%
summarise(taxa_reforma = mean(reforma), n_dados = n()) %>%
filter(n_dados > 100) %>%
mutate(
se = sqrt(taxa_reforma * (1 - taxa_reforma) / n_dados),
lower = taxa_reforma - qnorm(0.975) * se,
upper = taxa_reforma + qnorm(0.975) * se,
rejeita_h0 = abs(taxa_reforma-0.5) > qnorm(0.975)* se
) %>%
ggplot(aes(x = camara, y = taxa_reforma, color = rejeita_h0)) +
geom_point(size = 3) + # Mean points
geom_errorbar(aes(ymin = lower, ymax = upper), width = 0.2, color = "black") +
geom_hline(yintercept = 0.5, linetype = "dashed", color = "red") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
ylab("Taxa de Reforma") +
xlab("Câmara de Direito Penal") +
labs(color = "Rejeita Hipótese")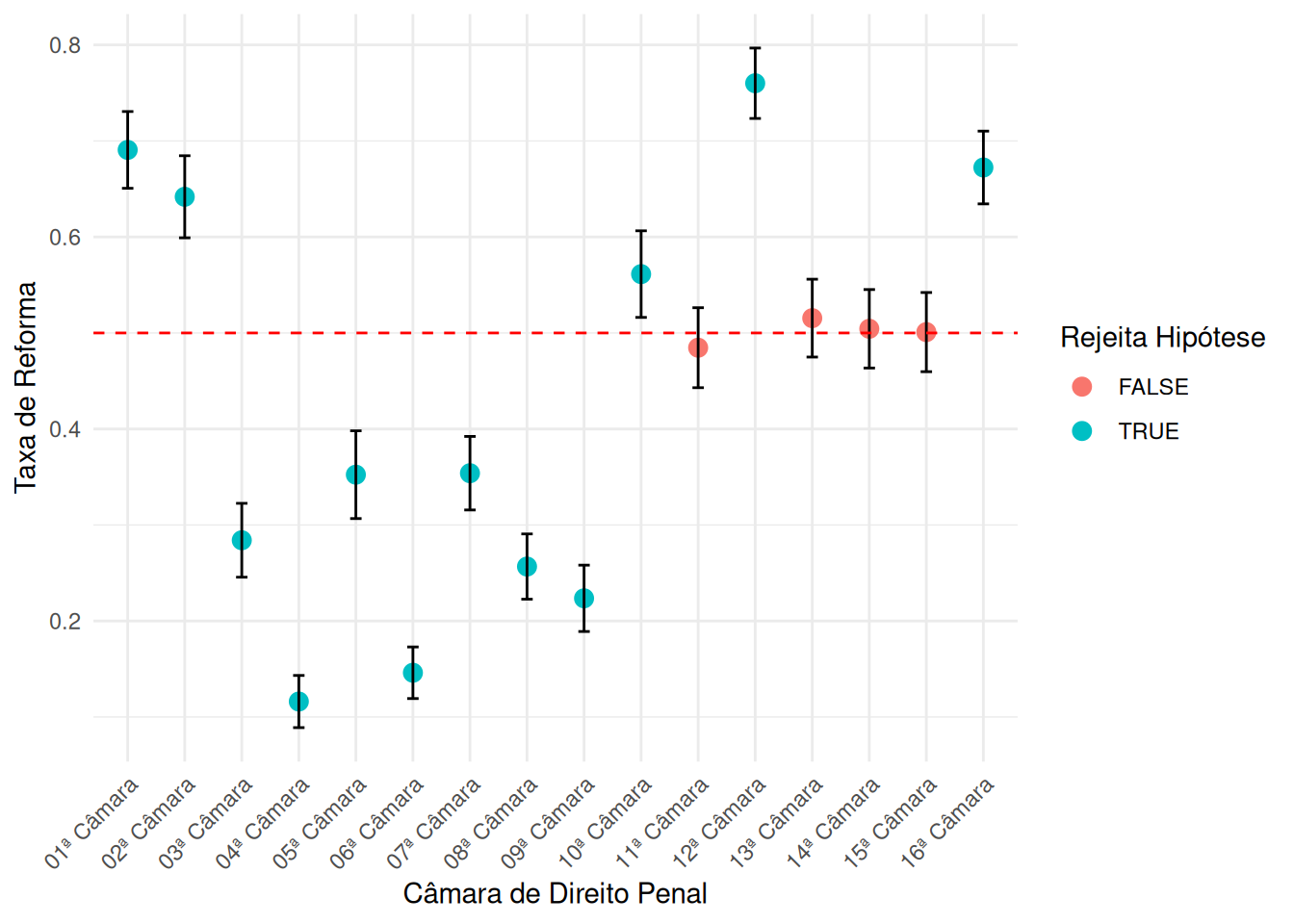
Exemplo: Amostra Normal
Considere que \(X_1, \ldots, X_n\) indicam o valor da causa em processos independentes e que \(X_i \sim \text{N}(\mu,\sigma^2)\). Rejeitamos \(H_0: \mu = \mu_0\) se
\[|\bar{X}-\mu_0| > \frac{S \cdot qnorm(1-0.5\alpha)}{\sqrt{n}}.\] Observação: Verifique \(H_0\) é rejeitado quando o intervalo de confiança 95% para \(\mu\) não contém o valor \(\mu_0\).
P-valor
Considere que se fixássemos \(\alpha = 0.05\), então o teste rejeitaria a hipótese nula. Por outro lado, se fixássemos \(\alpha = 0.01\), o teste não rejeitaria a hipótese nula. Em geral, quanto menor o valor de \(\alpha\), mais o teste fica conservador em rejeitar \(H_0\). Decorre deste comportamento que, enquanto que para valores “grandes” de \(\alpha\), o teste rejeitará \(H_0\), para valores “pequenos” de \(\alpha\) o teste não rejeitará \(H_0\).
Um valor de interesse é o menor \(\alpha\) tal que o teste rejeita \(H_0\) para a amostra observada. Este \(\alpha^*\) é comumente chamado de p-valor. Este valor pode ser muito útil para compartilhar resultados. Note que, para a amostra observada, se um pesquisador fixar um \(\alpha > \alpha^*\), então ele rejeitará \(H_0\). Por outro lado, se ele fixar \(\alpha < \alpha^*\), então não rejeitará \(H_0\). Assim, somente comparando o p-valor com o \(\alpha\) fixado, é possível saber o resultado do teste. Portanto, mesmo pesquisadores fixando níveis de significância diferentes podem saber o resultado do teste de hipótese apenas observando o p-valor.
Exercícios
Descreva em suas próprias palavras: teste de hipótese, erro tipo I, erro tipo II, nível de significância e p-valor.
Um cientista mede um objeto \(9\) vezes com um paquímetro e observa os valores em mm de: 1.2, 1.4, 1.7, 1.3, 1.5, 1.1, 1.8, 1.4, 1.1. Se as medições com o paquímetro tem desvio padrão de 0.2 mm, o pesquisador consegue rejeitar a hipótese de que o comprimento do objeto é menor do que \(1.3 mm\)? Qual o p-valor para esta hipótese na amostra observada?
Considere o caso da normal com variância conhecida. Ou seja, cada observação é tal que \(X_{i} \sim N(\mu,\sigma_0^2)\). Considere que desejamos testar \(H_0: \mu \geq \mu_0\). Neste caso, faria sentido calcular como evidência contra \(H_0\) o quanto \(\bar{X}\) é menor que \(\mu_0\)? Se sim, rejeitaríamos \(H_0\) quando \(\bar{X}-\mu_0 < c\). Utilizando passos análogos ao da seção da normal com variância conhecida, o valor de \(c\) tal que a probabilidade de erro tipo I é controlada por \(\alpha\). Determine o p-valor deste teste.
Considere novamente o caso da normal com variância conhecida, ou seja, cada observação é tal que \(X_{i} \sim N(\mu,\sigma_0^2)\). A medida \(|\bar{X}-\mu_0|\) captura evidência contra \(H_0: \mu = \mu_0\)? Se desejamos rejeitar \(H_0\) quando \(|\bar{X}-\mu_0| > c\), determine o valor de \(c\) que controla o erro tipo I em \(\alpha\). Determine o p-valor deste teste.